


Tego typu programy to złożone produkty, przeznaczone do zapisywania i analizowania podstawowych danych procesowych. Odgrywają bardzo ważną rolę w skutecznej analizie danych gromadzonych w zakładzie i podejmowaniu na ich podstawie właściwych decyzji.
Takie oprogramowanie ma wbudowane funkcje zapisu, analizy i wizualizacji danych oraz ich ekspozycji dla interfejsu programowania aplikacji (Application Program Interface – API), a nawet wysyłania komunikatów alarmowych. Może więc być wykorzystane np. do diagnozowania problemów ze sprzętem. Jeśli np. jakieś urządzenie pracujące na hali fabrycznej nagrzewa się bardziej niż zwykle, należy monitorować odczyty jego temperatury, co pozwoli stwierdzić, czy temperatura rośnie w czasie oraz o ile stopni. Taka wiedza umożliwia z kolei podjęcie w odpowiednim czasie decyzji o naprawie lub wymianie urządzenia.
Przechowywanie danych
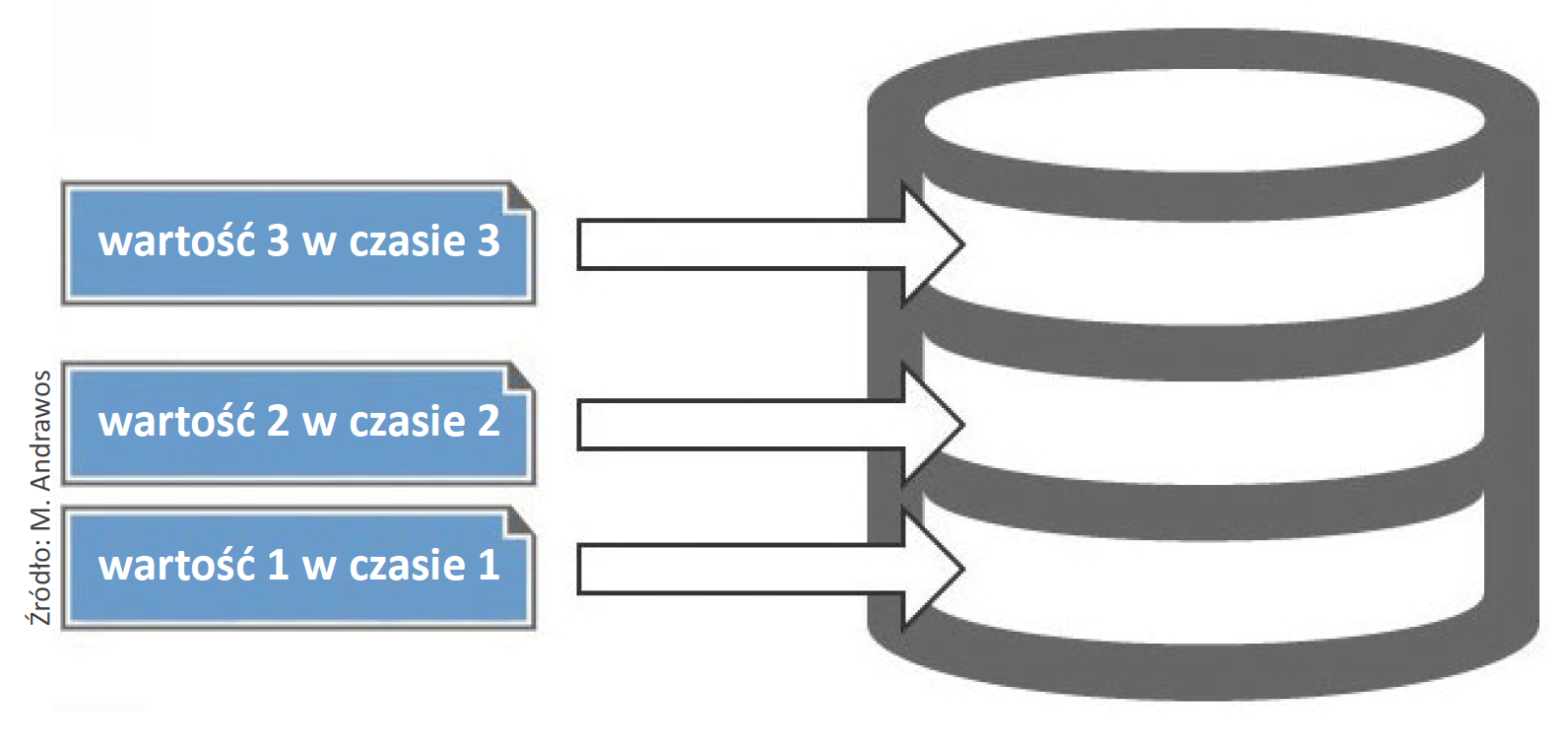
Programy do archiwizacji danych procesowych są wyspecjalizowanymi narzędziami z kategorii baz danych, zwanymi bazami danych szeregów czasowych.
Taka baza dołącza znacznik czasu do każdych nowo otrzymywanych danych, a następnie je zapisuje w takiej kolejności, w jakiej zostały odebrane (rys. 1), działając jako tzw. logger danych. Bazy danych szeregów czasowych zwykle nie wymagają formowania złożonych relacji pomiędzy różnymi punktami danych, gdy je zapisują. Inaczej mówiąc, baza danych szeregów czasowych zmienia się w ciągu pewnego czasu.
Programy do archiwizacji danych procesowych zaliczają się do kategorii nierelacyjnych baz danych (Not only Structured Query Language – NoSQL). Z drugiej strony relacyjna baza danych, która jest najbardziej rozpowszechnionym silnikiem baz danych, przechowuje dane w tabelach z rzędami i kolumnami (rys. 2). Użytkownik definiuje złożone relacje między tymi tabelami, sposób wpływania zmian w jednej tabeli na inne itd. Wprowadza to zbyt duży zamęt w bazie danych szeregów czasowych. Większość ze skomplikowanych algorytmów, które są wykorzystywane w relacyjnych bazach danych do tworzenia rzędów, kolumn i wydajnych relacji pomiędzy tabelami, stanowi nadmierny ciężar, a w zasadzie zbędny balast, jeśli użytkownik musi tylko zapisać jakieś dane ze znacznikiem czasowym. Typowe przykłady relacyjnych baz danych to serwer Microsoft SQL lub MySQL.

Funkcje oprogramowania
Programy do archiwizacji danych procesowych mają kilka funkcji, które mogą przynieść korzyści ich użytkownikom:
➡ Mają wstępnie wbudowane równania do analizy danych, ikony do ich wizualizacji oraz arkusze kalkulacyjne. Ponadto mają różne opcje równań do obliczania sprawności, mocy, tablice z wartościami parametrów, gotowe do użytku ikony urządzeń przemysłowych itp.
➡ Są w bardzo dużym stopniu kompatybilne z pakietami oprogramowania przemysłowego, zwykle wykorzystywanego w sterowaniu procesami technologicznymi i produkcji, takimi jak interfejsy operatorskie (HMI), rozproszone systemy sterowania (DCS) oraz inne sterowniki urządzeń i programy do regulacji.
➡ Wykorzystują wyspecjalizowane algorytmy do kompresji danych i oszczędzania przestrzeni dyskowej. Na przykład, jeśli dana wielkość/parametr jest równy 1 w chwili czasowej 1 oraz równy 1,0001 w chwili czasowej 2, to w większości wypadków nie jest konieczne zapisywanie w bazie wartości 1,0001, ponieważ nie wpłynie ona w dużym stopniu na analizę danych. W miarę upływu czasu oszczędza się w ten sposób dużo przestrzeni na dysku i w zasobach, zaś kompresja tego typu może być wyłączona, jeśli jest niepotrzebna.
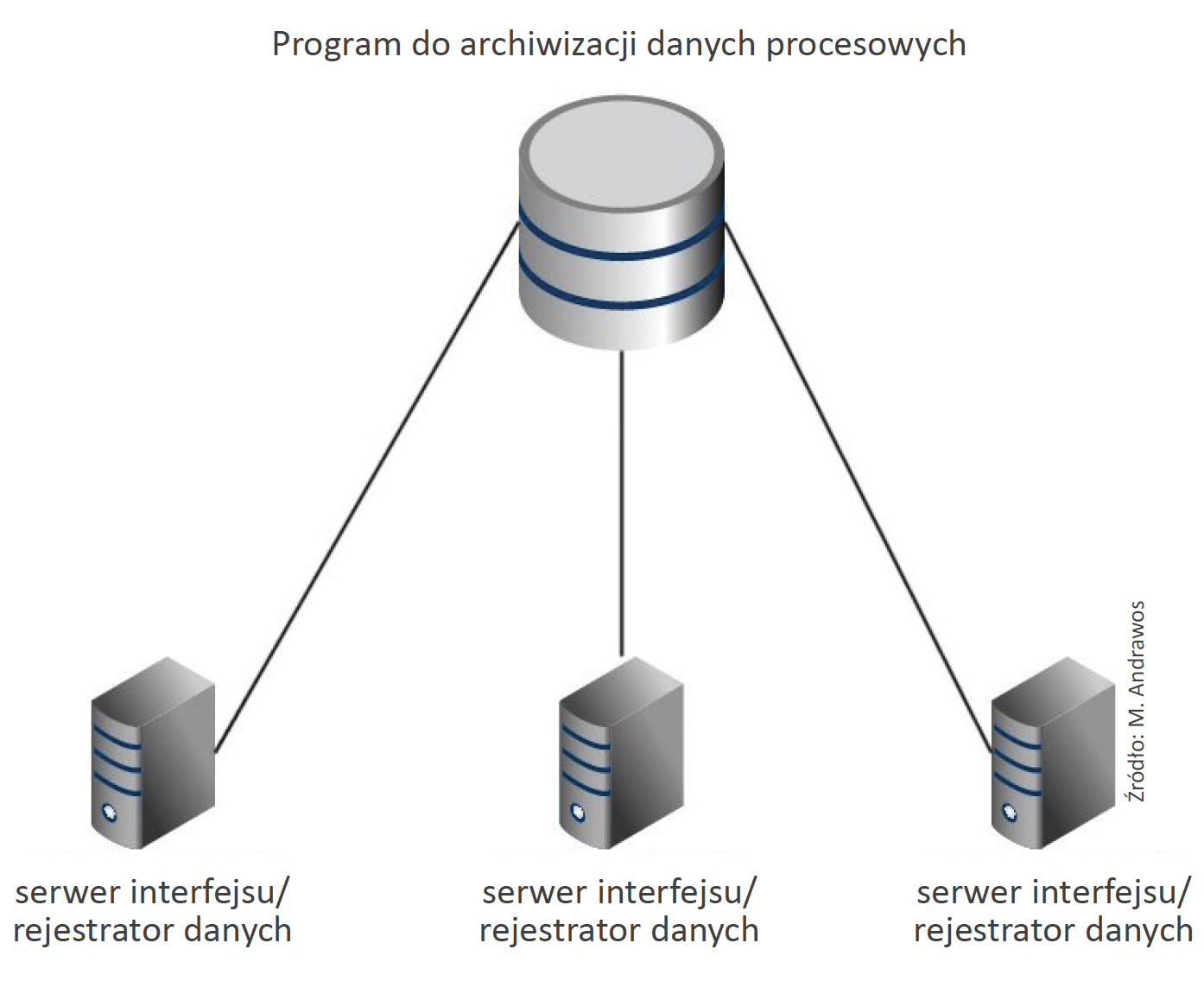
➡ Są często oferowane w postaci wstępnie przygotowanych pakietów z interfejsami będącymi odrębnymi programami, które mogą być wykorzystane w obiektach w celu bliskiego monitorowania pracy małych czujników i sterowników, podczas gdy sam program do archiwizacji danych procesowych znajduje się w centrum danych fabryki lub w tzw. chmurze (rys. 3). Warto jednak podkreślić, że nie jest korzystne instalowanie programu do archiwizacji danych procesowych bezpośrednio np. przy każdym czujniku, ponieważ jest on stosunkowo wymagający. Zamiast tego użytkownik powinien zainstalować wspomniany interfejs, którego obsługa w mniejszym stopniu obciąża zasoby i moce obliczeniowe urządzenia i może komunikować się z czujnikiem lub sterownikiem przed przekazaniem danych do centralnego programu archiwizującego.
➡ Funkcja przekazywania informacji przez węzeł pośredniczący (store-and-forward) jest niezbędna dla programów do archiwizacji danych historycznych, ponieważ brak jakiegoś fragmentu danych może skutkować wykonaniem ich nieprawidłowej analizy, co może prowadzić do podjęcia przez kierownictwo zakładu błędnej decyzji. Natomiast metoda store-and–forward gwarantuje, że dane nie zostaną utracone, nawet gdy centralny program archiwizujący utraci połączenie ze zdalnym interfejsem. Ten zdalny interfejs wykryje, że program archiwizujący nie odbiera danych, i rozpocznie zapisywanie danych zbieranych w wewnętrznym buforze lokalnym. Gdy połączenie z programem archiwizującym zostanie przywrócone, interfejs wyśle dane do tego programu.
Programy do archiwizacji danych procesowych zwykle buforują ostatnie dane bezpośrednio w pamięci komputera przed ich trwałym zapisaniem na twardym dysku. Jest to bardzo wydajne podejście dla analizy danych i obliczeń wykonywanych na nowszych danych, co zwykle jest wykorzystywane do wykrycia nagłych niespodziewanych sytuacji czy stanów w produkcji, zanim staną się one znaczącymi problemami.
Zamknięty vs. otwarty kod źródłowy
Programy do archiwizacji danych procesowych mają zamknięty kod źródłowy, co oznacza, że są drogie. W dużym stopniu są one uzależnione od produktów Microsoft: chmury obliczeniowe oparte są na platformie Azure, skrypty – na interpreterze Windows PowerShell, portale internetowe – na technice Silverlight, a zestawy do tworzenia oprogramowania – na języku Visual C++ (VC++) lub platformie NET Framework (.NET). Obecnie rozwiązania techniczne w tym obszarze zmierzają w kierunku wykorzystania jako podstawy języka HTML5.
Świat oprogramowania otwartego (open source) oferuje wiele opcji dla baz danych szeregów czasowych, które obecnie mogą być przerobione na programy do archiwizacji danych procesowych, pod warunkiem że zostanie dokonana właściwa inwestycja i włożona odpowiednia energia w to przedsięwzięcie. Jednak przeszkody stojące na drodze ku temu nie są trywialne, a ponadto firmy z branży przemysłowej do tej pory nie przykładały wagi do takich inwestycji.
Dwie cechy programów z otwartym kodem źródłowym, które mogą wnieść nową wartość dodaną do programów do archiwizacji danych procesowych, to tzw. sharding i przetwarzanie rozproszone danych (distributed data processing). Sharding („rozłupywanie na kawałki”) jest procesem rozłożenia danych obciążających serwer na wiele jego węzłów, przy jednoczesnym utrzymaniu śledzenia dróg wysłanych danych. Sharding wykorzystuje pewne wyspecjalizowane algorytmy przeznaczone do tego, by zapewnić, że gdy klient żąda danych, to algorytm pomaga w wybraniu tych węzłów, które hostują interesujące klienta dane, a następnie dostarcza te dane do klienta. Sharding jest niezbędny do obsługi bardzo dużych obciążeń danymi w celu zagwarantowania, że te dane nie zapchają serwera. Bez shardingu skalowalność staje się problemem, ponieważ organizacja wykorzystująca te dane się rozrasta.
„Przetwarzanie rozproszone danych” jest funkcją konieczną dla organizacji, w których niezawodne mechanizmy analityki wielkich ilości danych (data crunchers) mają znaczenie krytyczne, takich jak Google czy Amazon. Zasady przetwarzania rozproszonego polegają na podzieleniu bardzo skomplikowanych obliczeń na mniejsze, wykonaniu ich w rozproszonych węzłach serwerów, pobraniu otrzymanych wyników i połączeniu ich za pomocą mniej skomplikowanych obliczeń. Technika ta sprawia, że moc obliczeniowa dowolnego silnika analitycznego staje się dosłownie nieograniczona.
Podsumowanie
Programy do archiwizacji danych procesowych mogą niezależnie od gałęzi przemysłu przynieść firmom sukces i zapewnić długoletnie funkcjonowanie na rynku, pod warunkiem że są dobrze rozumiane i prawidłowo wykorzystywane.
Mina Andrawos jest inżynierem w zespole zajmującym się informatycznymi systemami sterowania procesami technologicznymi i produkcyjnymi w firmie Bloom Energy.

")
